[Review]Transfusion: Understanding Transfer Learning for Medical Imaging
This is my attempt to write and explain using my own words the joint paper from Google Brain and Cornell University published in NIPS 2019. The paper discussed the central questions of transfer learning. Here is a link to the paper:
https://arxiv.org/abs/1902.07208
Disclaimer
If you do not know why I am doing this, you can read my previous article that meticulously tries to explain the purpose of this article.

Recognition and appreciation
If I have seen further, it is by standing on the shoulders of giants. Special appreciations to the authors of the paper: Maithra Raghu, Chiyuan Zhang. Jon Kleinberg and Samy Bengio.
For your notice
I was excited about this paper because the different research papers I had previously read about transfer learning had different opinions about the performance. I was eager to see what this will unfold.
What is transfer learning?
Transfer learning is a supervised deep learning technique which involves using a previously trained model on a particular task as the starting point for a new task. A model, in its pristine state, has no knowledge of the world or what the data to be used looks like. The structure of the model begins as random guesses before an established pattern is observed. In transfer learning, you can either transfer all of the previous knowledge or a part of it. Medical imaging such as MRI and CT scan, cost an arm and a leg. Because of this, medical images are not readily available to train deep learning from scratch. Also, medical images are difficult to deal with because there are various types and variations. One fascinating study titled: How far have we come? Artificial intelligence for chest radiograph interpretation echoes this insight.
Lack of yet million medical images to train deep learning from scratch. Because of this, transfer learning is employed ( algorithms are initially trained on non-medical images (ImageNet) can be fine-tuned to work with medical images which decreases the need for large training datasets)
Due to this, transfer learning technique is frequently used in medical images. However in transfer learning, you can either transfer all of the previous knowledge or a part of it. This is because even though there are large image datasets that contains features that can be applied in the new task, there still exists some differences that cannot be applied to the medical domain. This paper discussed the central questions for transfer learning by exploring the properties involved in medical imaging by observing:
- Performance
- Learned representations and features
- Weight scalings
Deep learning trend
Inspired by Sambit Mahapatra’s post titled: Why Deep Learning over Traditional Machine Learning that attempts to illustrate why Deep Learning is gaining much popularity, I decided to do a quick Google trend to understand the trend distribution for “deep learning with medical imaging” and “machine learning with medical imaging”
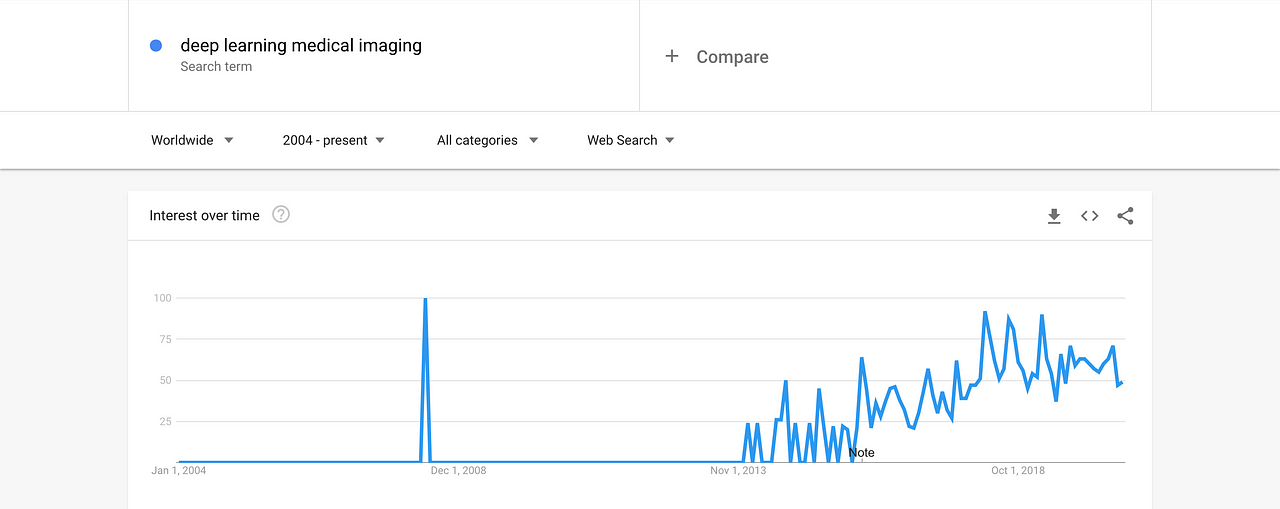
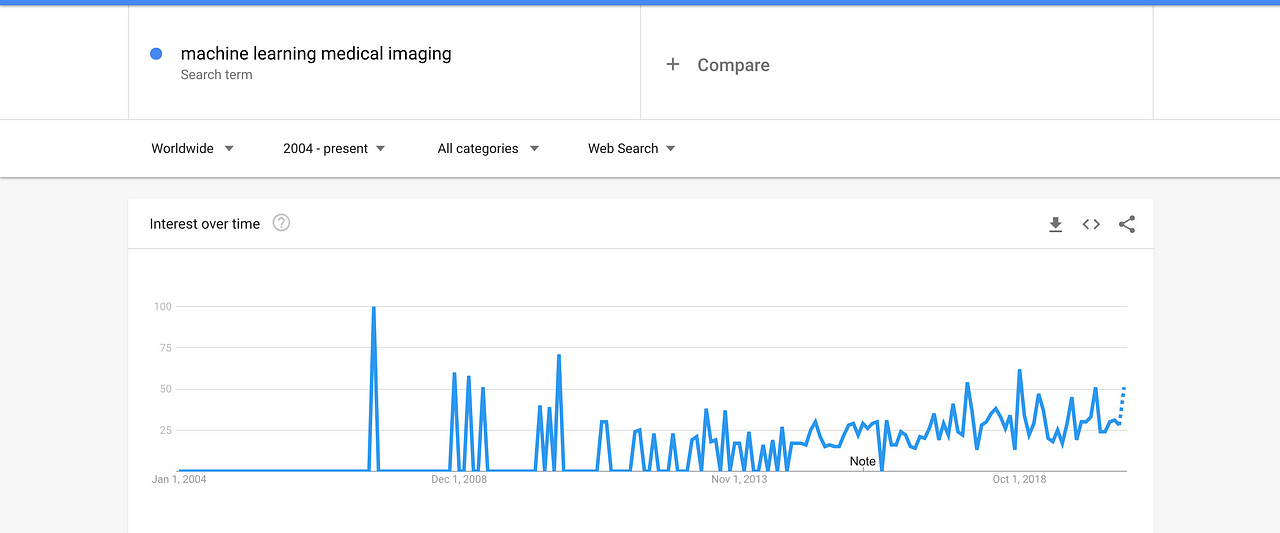
Due to the ramp up in the applications of deep learning as compared to machine learning, the popularity of transfer learning applications grew quickly especially in more prominent areas in radiology and ophthalmology because it doesn’t require a lot of data when a pretrained architecture like ResNet, DesNet, Inception etc., is used.
Transfer learning prides in the ability to save training time and a better performance of neural network especially with little data. However, there have been series of research that tries to invalidates this.
- COCO dataset experiment: This experiment carried out by Kaiming et al., in Rethinking ImageNet Pre-training whereby instance segmentation and object detection were performed using models trained from random initialisation and ImageNet pretrained models. The results from both models obtained were not far apart which brings the performance ability of transfer learning in question.
- In Do better ImageNet models transfer better by Simon et al.,experiment result shows that ImageNet architectures such as VGG16 generalizes across datasets but the features are less general regardless of the dimensionality reduction strategy employed. This is because ImageNet features and medical images features have considerable differences.
There has been series of research and postulations such as the use of heavy data augmentation techniques, slow learning rates and larger number of epochs while using transfer learning will lead to a faster convergence during training.
Transfer learning in medical imaging however has faced some major setbacks due to the variations and small-sized medical images. For instance, focusing on the wrong receptive field and the convolution network is extracting the wrong sections of the image will lead to a slower convergence during training.

Also, the variation in number of classes and the size of the dataset is another factor that affects transfer learning in medical domain.
Paper Contributions
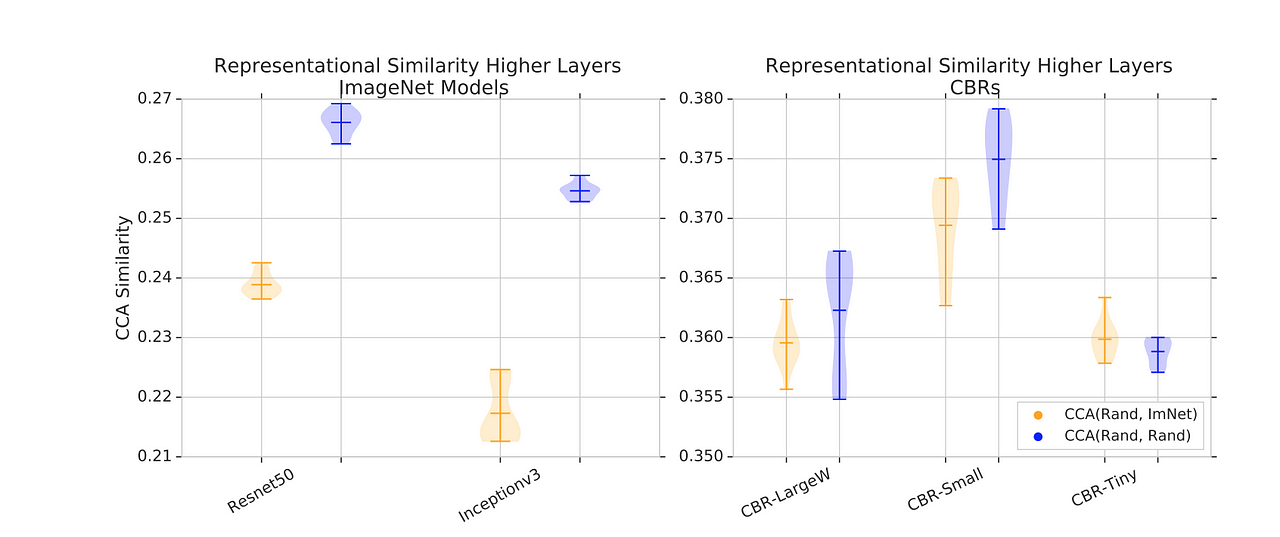
This paper compares the performance of ResNet50 and Inception-v3 for natural images such as ImageNet using transfer learning as well as non-standard architectures using random initialization on RETINA data and cheXpert data for which transfer learning can be used. Also, a family of smaller convolutional architecture dubbed CBR was designed with size ranging from one-third to one-twentieth of the standard ImageNet model size.
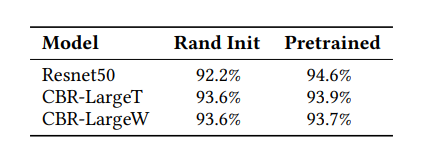
From this experiment, it was observed that the performance of the medical imaging tasks is not significantly improved with or without transfer learning.
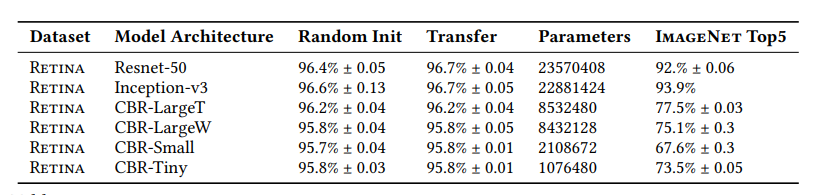
Here, the tiny model architecture for the RETINA dataset has very similar performance with the Resnet-50 architecture with or without transfer learning.
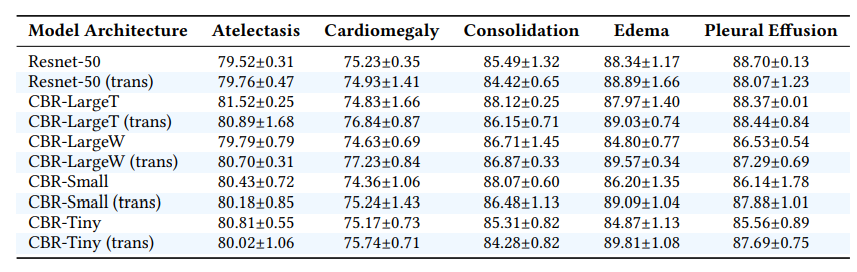
From the result above, the use of transfer learning doesn’t considerably lead to a better performance. Also the CBR-Tiny has 100 times less parameter than Resnet-50 but it gets a better result than the Resnet-50. Therefore, it is better to first of all train with a simple model before training with a large model.
Also, another experiment was carried out using 5,000 datapoints (smaller model) only in the RETINA dataset. This is because most medical datasets are considerably smaller in size than ImageNet.
Examining the effect of transfer learning, using a pretrained model gives better result.

Figure a and c shows the convolution filter before training. They look almost the same and random. Using transfer learning in figure c and g, the features actually look better and it is not random. Now looking at figure b and f, a few of the signals changed in f, but most in b are still random. In essence, smaller model has a better chance of learning on a smaller dataset than a bigger model. It is also observed that canonical correlation analysis (CCA) similarity score which tries to understand the correlation between two weighting components tend to be higher in figure a and b compared to figure e and f.
In conclusion, the last pages of the paper explained the importance of weight transfusion which is an hybrid approach to transfer learning involving keeping the first few layers of the network fixed while fine tuning the rest of the layers.
Further readings

Tobiloba Adejumo Newsletter
Join the newsletter to receive the latest updates in your inbox.
![[Review] How Far Have We Come? Artificial Intelligence for Chest Radiograph Interpretation](/content/images/size/w1384/2021/07/-Review--How-Far-Have-We-Come-Artificial-Intelligence-for-Chest-Radiograph-Interpretation.png)
{kind=link}