
How I Fell In Love With Machine Learning
Machine learning is all about finding patterns in data and then using these patterns to predict the future.
Who Should Read?
This article focuses on understanding machine learning from a beginners perspective. If you find it very difficult to understand the hype about machine learning, and also why you should certainly ride the wave of the hype, then this article was written for you.
Prerequisites
I assume you are good at keeping secrets and you are not judgmental—those are the only requirements I need in this article.
My Confession
Let’s forget about the serious and scientific machine learning definitions for now. We are all involved in machine learning one way or the other, but we do not know because our involvement is rather subtle. My love for machine learning increased after I watched the series, “Person Of Interest”
The series centers on a mysterious reclusive billionaire computer programmer named Harold Finch, who develops a supercomputer for the federal government known as “The Machine” that is capable of collating all sources of information to predict and identify people planning terrorist acts. This supercomputer named “The Machine” has the uncanny ability to tell if a person will be in trouble thus providing sufficient information to allow the government act on it. You can imagine the amount of data that “The Machine” possesses— data for millions of population.
Machine learning is all about finding patterns in data and then using these patterns to predict the future. Sometimes, it is referred to as predictive analytics because it uses both new and old data (historical data) to predict future events. It is practically an extension of classic analytics (data mining). Data mining actually involves finding patterns in data but it doesn’t learn and apply knowledge on its own without human interaction. Data mining also can’t automatically see the relationship between existing pieces of data with the same depth that machine learning can. Also there are some badass machine learning algorithms responsible for this that data mining do not know about.
The Learning Process
How did you learn how to read?
Learning how to read involves identifying patterns, right? You identify letters and the patterns of letters when used together to form a word. You then had to recognise those patterns when you saw them again. Similarly, machine learning operates the same way.
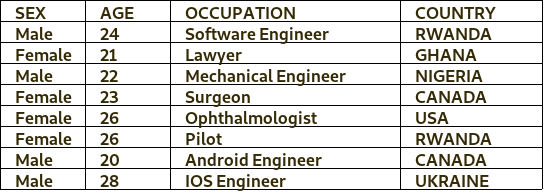
But the thing about machine learning is this: If you consider the example in Table 1 above, it is easy to identify the patterns in this data. For instance, if you stare at the table closely enough, you will notice that only the males are engineers, so anytime there is a female coming in from any country in the world, automatically she’s not an engineer. But does this conclusion hold? Don’t we have really good female engineers? Of course we do! In fact, we have excellent female engineers from different countries in the world.
We cannot have a generalized predictive outcome based on this data because the data is not enough for us to conclude. Let’s imagine a dataset that contains over 35,000 data entries. No amount of “data staring” can make you achieve a predictive rule because of the size of the data. This is where machine learning comes in.
Machine learning has the ability to find the patterns in data. You start with the data that contains the patterns. You feed that data into a machine learning algorithm that finds the patterns in the data. This algorithm generates or creates something called a model. This model is like an external brain that can recognises pattern when presented with new data. Different applications can now then use this model by supplying new data and to see if the new data matches known patterns.
Why is Machine Learning So Hot Right Now?
- There are lots of generated data everywhere. This means that there are likely chances we predict the future because of many test cases.
- Presence of computing power: We are in the cloud era so if your system doesn’t have the ability to predict the future, it is possible to simulate everything on the cloud.
- Scientist are not joking; they mean business. There are lots of machine learning algorithms available and more are still coming.
Who is Interested in Machine Learning?
- Business Leaders: They want solutions to their problems such as fraudulent transactions and customer engagement services. They want to be able to predict a customer leaving them before they do. They want to predict what a customer wants before they ask.
- Software Developers: They want to create better applications and make their applications rely on the generated or created models by machine learning, otherwise known as an external brain by me, to make better predictions. Machine learning can help you create smarter applications even though you are not the one who created the models.
- Data Scientist: This is the sexiest job of the 21st century. The data scientist wants better, easy-to-use and powerful tools. A data scientist is someone who knows about three things: Statistics, Machine Learning Softwares and a Problem Domain they want to solve.
Machine Learning as a Service.
Have you ever used Microsoft Word?
If you have, then I’m quite sure you have also heard of Google Docs. Google Docs is much more powerful than Microsoft Word because it supports real-time collaboration. Google Docs is an example of a service.
Although, we can make use of machine learning algorithms offline which is a very tedious process, some vendors have developed it as a service. Machine learning as a service is called Machine learning Offerings. Some of this vendors include: SAS Analytics Suite, RapidMiner Studio, Alteryx Analytics, IBM SPSS, SAP Predictive Analysis, Oracle Advanced Analytics, Microsoft Azure Machine Learning and Amazon Machine Learning.
Does Machine Learning Involve Programming?
Of course it does! A machine learning technology that is worth mentioning is called R. R is an open source programming language and environment that supports machine learning, statistical computing and a lot more. It has lots of available packages to address machine learning problems. Many machine learning offerings support R but R is not the only choice. Python is also increasingly popular as the open source technology for doing machine learning. Although, R is no longer alone as the only open source choice, but it is still the most popular.
Is Machine Learning Boring?
Machine learning is 50 percent boring 😃. I can’t even lie. Why is this so? Machine learning is pretty iterative; you repeat things over and over again. Also, it is really challenging. Imagine working with over 45,000 data entries, trying to find patterns. It is really tedious and confusing, but sometimes it’s fun IF you eventually figure it out. I know why I used if instead of when because sometimes, you might not even find anything.
The Two Important Questions You Need To Ask Before Using Machine Learning
- Do you have the right data to solve this problem?: Imagine you want to detect a credit card fraud, you must know that some historical data will be needed. You can’t just go ahead collecting data entries like: favourite food or parent’s name.
- Do you know how to measure success?: Machine Learning is an iterative process. When will you stop iterating? How will you measure success. Are you interested in achieving 95percent accuracy or 100percent accuracy, or maybe 80percent.
The Biggest Problem In Machine Learning
Choosing the data is practically the biggest challenge with machine learning. Before choosing the data, you first need to consult domain experts in the field so as to know the right features to be used rather than asking for name of a patient when predicting for future occurrences of diabetics. The domain experts might help you with choosing the data but certainly won’t help you with cleaning of the data. The data is never organized as there will be missing tables, repeated values which will create a wrong model when made use of. It is very essential to spend ample time in cleaning the data so you can get better predictions.
After creating the model, the first created model is referred to as the candidate model. Is the first model you create the best one? No. You then iterate using the machine learning algorithms until you select a final model The selected model is the deployed model that applications that can use of. You need to recreate your models regularly because the world changes which means, your data set will keep changing and you iterate until you have a model that makes good predictions.
Machine Learning Jargons
Training Data: This is referred to as the prepared data that is used to create the model after you have preprocessed or cleaned the data. Why is this called training data in Machine Learning? It is called training data because in the parlance of Machine Learning, creating or generating a model is called training a model.
Features: This are referred to qualities of the data. When data is tabularized, the features are the names of columns present in the data. In Table 1 above: sex, age, occupation and country are the features present in the data.
Categories of Machine Learning
There are two broad categories of machine learning: Supervised Learning and Unsupervised Learning. Supervised Learning simply means that the value you want to predict is contained in the training data. Unlike Unsupervised learning, whereby the value that you want to predict is not contained in the training data. Also supervised learning has the data labelled i.e you know what to expect, but in unsupervised learning, the data is unlabelled.
What’s Next?
On the next intermission, we will learn about some of the sub-categories of machine learning like regression, classification and clustering. We will also learn about some of the machine learning algorithms that can be used to solve problems such as use of decision tree, neural networks, bayesian, k-means algorithm e.t.c.
REFERENCES
- https://blog.g2crowd.com/blog/trends/artificial-intelligence/2018-ai/machine-learning-service-mlaas/
- Understanding Machine Learning by David Chappell
- https://www.import.io/post/data-mining-machine-learning-difference/
- School of AI

Tobiloba Adejumo Newsletter
Join the newsletter to receive the latest updates in your inbox.

